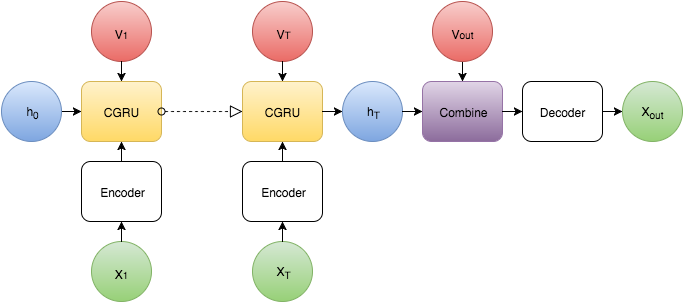
Convolutional Shape Encoder
An autoencoder is composed of a pair of networks, an encoder which takes a raw input and a decoder which reconstructs the input from the encoded vector. If trained properly the encoded vector will contain higher leverl features which can be used in tasks like classification or regression. Most work on autoencoders has focused on images, but can we encode other data?
I’ve been working for a while on trying to encode 3D objects. (For the 1 or 2 of you who’ve read my previous post, this is the same problem just an improved architecture). So the problem is thus: Given a sequence of glimpses of a 3D object, generate an encoding representing the full shape. The encoding should contain information about the full 3D shape such that a decoder can predict the appearance of the object from a given viewpoint .
Where and are input images and view vectors (4D coordinates - 3 normalized cylindrical coordinates r,theta,z representing the position of the camera and a 4th coord. z_look representing the point on the z axis the camera points at). is the output image from the decoder at view .
Architecture
Encoder
The encoder consists of 2 components. First each image (size 64x64) is passed through a 3 layer convolutional encoder. Each layer consists of a 5x5 convolution, ReLU activation and 2x2 max pooling. The final output of this component is a 64 x 8 x 8 tensor. The input view vector is transformed and reshaped into an 8 x 8 x 8 tensor . This is joined with and then passed into a Convolutional Gated Recurrent Unit (CGRU).
where
This is the same as the typical GRU architecture except the matrix multiplications are replaced with convolutions U,U’,U’’ and W,W,’W’’ (5x5 filters were used in this experiment). This is similar to the CGRU used in the “Neural GPU”1 except the inputs are passed in at each step instead of all put in the starting state.
The final output after T steps is the encoded shape tensor which is passed into the decoder.
Decoder
The decoder is also broken into 2 parts. The first part combines the information in the shape tensor and the output viewpoint . The viewpoint is transformed into an 8 x 8 x 8 tensor and appended to and then passed into another GRU like layer.
where
This is actually identical to the CGRU used in the Neural GPU, but I’ll call it CGRU2 just to distinguish it from the recurrent version.
The tensor is then passed through 2 more CGRU2 layers
The point of using the gated units is to allow signal and gradient information to bypass layers unchanged to allow for deeper networks without exploding/vanishing gradients. I’ve only used 3 layers so could could probably get away with just convolutions without any of the gates, but this allows me to scale up without much need for fine tuning and careful initialization.
This tensor is passed into a convolutional decoder with a symmetrical architecture to the first stage encoder. (i.e. 3 layers,5x5 convolutions,2x2 unpooling).
The final output image is then compared against a target render taken at . For training I use a squared error loss function
And the error is propagated back through the entire decoder and encoder. Training takes place by encoding the input glimpses once to obtain shape tensor . Then this tensor is passed into the decoder at different viewpoints and gradients are passed backwards through the decoder. These gradients are all added and divided by the number of targets (I used 16 targets for each object). Then this is back propagated through the encoder. For more details see this post. The architecture of that last experiment is pretty different but training is more or less the same.
Results
After training the average squared error on validation set is less than 0.0024, which leads to the output images coming out pretty similar visually to the targets they’re tested against. (OK it does a pretty bad job on the glasses)
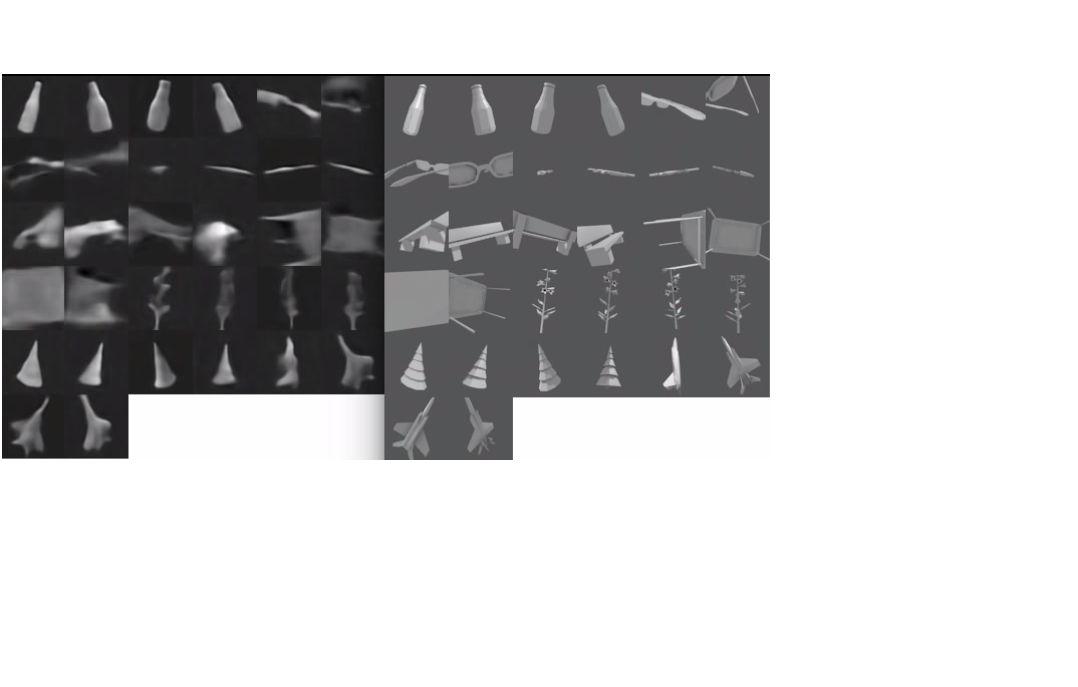
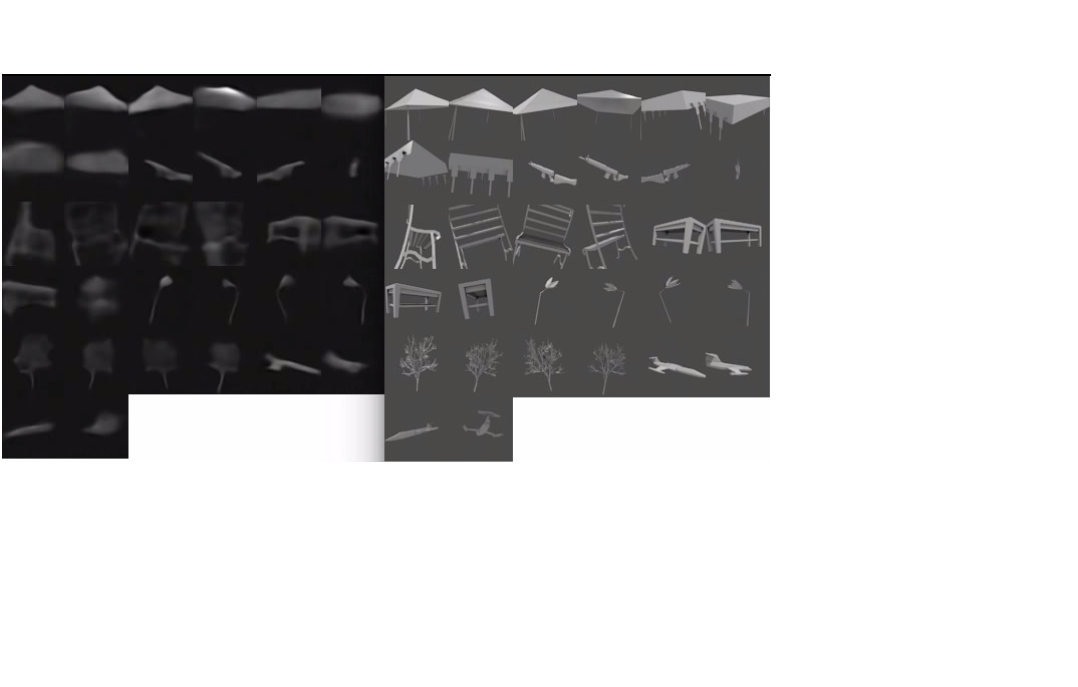
Also the network is able to learn a smooth function for viewpoint transformations. Below is a video of different samples with the shape tensor held fixed with the viewpoint vector allowed to vary. First the theta (rotation angle) parameter is sampled across 80 values between -1 and 1. Then the z coordinate varies between -.2 and .2 (the maximum range in the training set) at different values of theta.
(Skip to ~3:20 to just see the test examples.) Most of the jankiness is due to video encoding and not the network itself. Seeing the network’s predictions in motion gives solid evidence that the 3D shape of the object has been encoded into the 72 x 8 x 8 tensor and that the decoder is able to successfully extract that information. These are the results from my first run after changing the architecture to be fully convolutional. With more fine tuning (number of layers,dropout) I can probably get the error even lower, but I’m satisfied with the general form of the architecture.
-
http://arxiv.org/abs/1511.08228 ↩